mirror of
https://github.com/correl/dejavu.git
synced 2025-04-01 09:05:55 -09:00
moved to github
This commit is contained in:
commit
90a93bc47b
15 changed files with 962 additions and 0 deletions
7
.gitignore
vendored
Normal file
7
.gitignore
vendored
Normal file
|
|
@ -0,0 +1,7 @@
|
|||
*.pyc
|
||||
wav
|
||||
mp3
|
||||
*.wav
|
||||
*.mp3
|
||||
.DS_Store
|
||||
*.cnf
|
||||
BIN
README.md
Normal file
BIN
README.md
Normal file
Binary file not shown.
0
dejavu/__init__.py
Normal file
0
dejavu/__init__.py
Normal file
106
dejavu/control.py
Normal file
106
dejavu/control.py
Normal file
|
|
@ -0,0 +1,106 @@
|
|||
from dejavu.database import SQLDatabase
|
||||
from dejavu.converter import Converter
|
||||
from dejavu.fingerprint import Fingerprinter
|
||||
from scipy.io import wavfile
|
||||
from multiprocessing import Process
|
||||
import wave, os
|
||||
import random
|
||||
|
||||
class Dejavu():
|
||||
|
||||
def __init__(self, config):
|
||||
|
||||
self.config = config
|
||||
|
||||
# create components
|
||||
self.converter = Converter()
|
||||
self.fingerprinter = Fingerprinter(self.config)
|
||||
self.fingerprinter.db.setup()
|
||||
|
||||
# get songs previously indexed
|
||||
self.songs = self.fingerprinter.db.get_songs()
|
||||
self.songnames_set = set() # to know which ones we've computed before
|
||||
if self.songs:
|
||||
for song in self.songs:
|
||||
song_id = song[SQLDatabase.FIELD_SONG_ID]
|
||||
song_name = song[SQLDatabase.FIELD_SONGNAME]
|
||||
self.songnames_set.add(song_name)
|
||||
print "Added: %s to the set of fingerprinted songs..." % song_name
|
||||
|
||||
def chunkify(self, lst, n):
|
||||
"""
|
||||
Splits a list into roughly n equal parts.
|
||||
http://stackoverflow.com/questions/2130016/splitting-a-list-of-arbitrary-size-into-only-roughly-n-equal-parts
|
||||
"""
|
||||
return [lst[i::n] for i in xrange(n)]
|
||||
|
||||
def fingerprint(self, path, output, extensions, nprocesses):
|
||||
|
||||
# convert files, shuffle order
|
||||
files = self.converter.find_files(path, extensions)
|
||||
random.shuffle(files)
|
||||
files_split = self.chunkify(files, nprocesses)
|
||||
|
||||
# split into processes here
|
||||
processes = []
|
||||
for i in range(nprocesses):
|
||||
|
||||
# need database instance since mysql connections shouldn't be shared across processes
|
||||
sql_connection = SQLDatabase(
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_HOSTNAME),
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_USERNAME),
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_PASSWORD),
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_DATABASE))
|
||||
|
||||
# create process and start it
|
||||
p = Process(target=self.fingerprint_worker, args=(files_split[i], sql_connection, output))
|
||||
p.start()
|
||||
processes.append(p)
|
||||
|
||||
# wait for all processes to complete
|
||||
for p in processes:
|
||||
p.join()
|
||||
|
||||
# delete orphans
|
||||
print "Done fingerprinting. Deleting orphaned fingerprints..."
|
||||
self.fingerprinter.db.delete_orphans()
|
||||
|
||||
def fingerprint_worker(self, files, sql_connection, output):
|
||||
|
||||
for filename, extension in files:
|
||||
|
||||
# if there are already fingerprints in database, don't re-fingerprint or convert
|
||||
song_name = os.path.basename(filename).split(".")[0]
|
||||
if song_name in self.songnames_set:
|
||||
print "-> Already fingerprinted, continuing..."
|
||||
continue
|
||||
|
||||
# convert to WAV
|
||||
wavout_path = self.converter.convert(filename, extension, Converter.WAV, output, song_name)
|
||||
|
||||
# insert song name into database
|
||||
song_id = sql_connection.insert_song(song_name)
|
||||
|
||||
# for each channel perform FFT analysis and fingerprinting
|
||||
channels = self.extract_channels(wavout_path)
|
||||
for c in range(len(channels)):
|
||||
channel = channels[c]
|
||||
print "-> Fingerprinting channel %d of song %s..." % (c+1, song_name)
|
||||
self.fingerprinter.fingerprint(channel, wavout_path, song_id, c+1)
|
||||
|
||||
# only after done fingerprinting do confirm
|
||||
sql_connection.set_song_fingerprinted(song_id)
|
||||
|
||||
def extract_channels(self, path):
|
||||
"""
|
||||
Reads channels from disk.
|
||||
"""
|
||||
channels = []
|
||||
Fs, frames = wavfile.read(path)
|
||||
wave_object = wave.open(path)
|
||||
nchannels, sampwidth, framerate, num_frames, comptype, compname = wave_object.getparams()
|
||||
assert Fs == self.fingerprinter.Fs
|
||||
|
||||
for channel in range(nchannels):
|
||||
channels.append(frames[:, channel])
|
||||
return channels
|
||||
54
dejavu/convert.py
Normal file
54
dejavu/convert.py
Normal file
|
|
@ -0,0 +1,54 @@
|
|||
import os, fnmatch
|
||||
from pydub import AudioSegment
|
||||
|
||||
class Converter():
|
||||
|
||||
WAV = "wav"
|
||||
MP3 = "mp3"
|
||||
FORMATS = [
|
||||
WAV,
|
||||
MP3]
|
||||
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
def ensure_folder(self, extension):
|
||||
if not os.path.exists(extension):
|
||||
os.makedirs(extension)
|
||||
|
||||
def find_files(self, path, extensions):
|
||||
filepaths = []
|
||||
extensions = [e.replace(".", "") for e in extensions if e.replace(".", "") in Converter.FORMATS]
|
||||
print "Supported formats: %s" % extensions
|
||||
for dirpath, dirnames, files in os.walk(path) :
|
||||
for extension in extensions:
|
||||
for f in fnmatch.filter(files, "*.%s" % extension):
|
||||
p = os.path.join(dirpath, f)
|
||||
renamed = p.replace(" ", "_")
|
||||
os.rename(p, renamed)
|
||||
#print "Found file: %s with extension %s" % (renamed, extension)
|
||||
filepaths.append((renamed, extension))
|
||||
return filepaths
|
||||
|
||||
def convert(self, orig_path, from_format, to_format, output_folder, song_name):
|
||||
|
||||
# start conversion
|
||||
self.ensure_folder(output_folder)
|
||||
print "-> Now converting: %s from %s format to %s format..." % (song_name, from_format, to_format)
|
||||
|
||||
# MP3 --> WAV
|
||||
if from_format == Converter.MP3 and to_format == Converter.WAV:
|
||||
|
||||
newpath = os.path.join(output_folder, "%s.%s" % (song_name, Converter.WAV))
|
||||
if os.path.isfile(newpath):
|
||||
print "-> Already converted, skipping..."
|
||||
else:
|
||||
mp3file = AudioSegment.from_mp3(orig_path)
|
||||
mp3file.export(newpath, format=Converter.WAV)
|
||||
|
||||
# unsupported
|
||||
else:
|
||||
print "CONVERSION ERROR:\nThe conversion from %s to %s is not supported!" % (from_format, to_format)
|
||||
|
||||
print "-> Conversion complete."
|
||||
return newpath
|
||||
320
dejavu/database.py
Normal file
320
dejavu/database.py
Normal file
|
|
@ -0,0 +1,320 @@
|
|||
import MySQLdb as mysql
|
||||
import MySQLdb.cursors as cursors
|
||||
import os
|
||||
|
||||
class SQLDatabase():
|
||||
"""
|
||||
Queries:
|
||||
|
||||
1) Find duplicates (shouldn't be any, though):
|
||||
|
||||
select `hash`, `song_id`, `offset`, count(*) cnt
|
||||
from fingerprints
|
||||
group by `hash`, `song_id`, `offset`
|
||||
having cnt > 1
|
||||
order by cnt asc;
|
||||
|
||||
2) Get number of hashes by song:
|
||||
|
||||
select song_id, song_name, count(song_id) as num
|
||||
from fingerprints
|
||||
natural join songs
|
||||
group by song_id
|
||||
order by count(song_id) desc;
|
||||
|
||||
3) get hashes with highest number of collisions
|
||||
|
||||
select
|
||||
hash,
|
||||
count(distinct song_id) as n
|
||||
from fingerprints
|
||||
group by `hash`
|
||||
order by n DESC;
|
||||
|
||||
=> 26 different songs with same fingerprint (392 times):
|
||||
|
||||
select songs.song_name, fingerprints.offset
|
||||
from fingerprints natural join songs
|
||||
where fingerprints.hash = "08d3c833b71c60a7b620322ac0c0aba7bf5a3e73";
|
||||
"""
|
||||
|
||||
# config keys
|
||||
CONNECTION = "connection"
|
||||
KEY_USERNAME = "username"
|
||||
KEY_DATABASE = "database"
|
||||
KEY_PASSWORD = "password"
|
||||
KEY_HOSTNAME = "hostname"
|
||||
|
||||
# tables
|
||||
FINGERPRINTS_TABLENAME = "fingerprints"
|
||||
SONGS_TABLENAME = "songs"
|
||||
|
||||
# fields
|
||||
FIELD_HASH = "hash"
|
||||
FIELD_SONG_ID = "song_id"
|
||||
FIELD_OFFSET = "offset"
|
||||
FIELD_SONGNAME = "song_name"
|
||||
FIELD_FINGERPRINTED = "fingerprinted"
|
||||
|
||||
# creates
|
||||
CREATE_FINGERPRINTS_TABLE = """
|
||||
CREATE TABLE IF NOT EXISTS `%s` (
|
||||
`%s` binary(10) not null,
|
||||
`%s` mediumint unsigned not null,
|
||||
`%s` int unsigned not null,
|
||||
INDEX(%s),
|
||||
UNIQUE(%s, %s, %s)
|
||||
);""" % (FINGERPRINTS_TABLENAME, FIELD_HASH,
|
||||
FIELD_SONG_ID, FIELD_OFFSET, FIELD_HASH,
|
||||
FIELD_SONG_ID, FIELD_OFFSET, FIELD_HASH)
|
||||
|
||||
CREATE_SONGS_TABLE = """
|
||||
CREATE TABLE IF NOT EXISTS `%s` (
|
||||
`%s` mediumint unsigned not null auto_increment,
|
||||
`%s` varchar(250) not null,
|
||||
`%s` tinyint default 0,
|
||||
PRIMARY KEY (`%s`),
|
||||
UNIQUE KEY `%s` (`%s`)
|
||||
);""" % (SONGS_TABLENAME, FIELD_SONG_ID, FIELD_SONGNAME, FIELD_FINGERPRINTED,
|
||||
FIELD_SONG_ID, FIELD_SONG_ID, FIELD_SONG_ID)
|
||||
|
||||
# inserts
|
||||
INSERT_FINGERPRINT = "INSERT IGNORE INTO %s (%s, %s, %s) VALUES (UNHEX(%%s), %%s, %%s)" % (
|
||||
FINGERPRINTS_TABLENAME, FIELD_HASH, FIELD_SONG_ID, FIELD_OFFSET) # ignore duplicates and don't insert them
|
||||
INSERT_SONG = "INSERT INTO %s (%s) VALUES (%%s);" % (
|
||||
SONGS_TABLENAME, FIELD_SONGNAME)
|
||||
|
||||
# selects
|
||||
SELECT = "SELECT %s, %s FROM %s WHERE %s = UNHEX(%%s);" % (FIELD_SONG_ID, FIELD_OFFSET, FINGERPRINTS_TABLENAME, FIELD_HASH)
|
||||
SELECT_ALL = "SELECT %s, %s FROM %s;" % (FIELD_SONG_ID, FIELD_OFFSET, FINGERPRINTS_TABLENAME)
|
||||
SELECT_SONG = "SELECT %s FROM %s WHERE %s = %%s" % (FIELD_SONGNAME, SONGS_TABLENAME, FIELD_SONG_ID)
|
||||
SELECT_NUM_FINGERPRINTS = "SELECT COUNT(*) as n FROM %s" % (FINGERPRINTS_TABLENAME)
|
||||
|
||||
SELECT_UNIQUE_SONG_IDS = "SELECT COUNT(DISTINCT %s) as n FROM %s WHERE %s = 1;" % (FIELD_SONG_ID, SONGS_TABLENAME, FIELD_FINGERPRINTED)
|
||||
SELECT_SONGS = "SELECT %s, %s FROM %s WHERE %s = 1;" % (FIELD_SONG_ID, FIELD_SONGNAME, SONGS_TABLENAME, FIELD_FINGERPRINTED)
|
||||
|
||||
# drops
|
||||
DROP_FINGERPRINTS = "DROP TABLE IF EXISTS %s;" % FINGERPRINTS_TABLENAME
|
||||
DROP_SONGS = "DROP TABLE IF EXISTS %s;" % SONGS_TABLENAME
|
||||
|
||||
# update
|
||||
UPDATE_SONG_FINGERPRINTED = "UPDATE %s SET %s = 1 WHERE %s = %%s" % (SONGS_TABLENAME, FIELD_FINGERPRINTED, FIELD_SONG_ID)
|
||||
|
||||
# delete
|
||||
DELETE_UNFINGERPRINTED = "DELETE FROM %s WHERE %s = 0;" % (SONGS_TABLENAME, FIELD_FINGERPRINTED)
|
||||
DELETE_ORPHANS = ""
|
||||
|
||||
def __init__(self, hostname, username, password, database):
|
||||
# connect
|
||||
self.database = database
|
||||
try:
|
||||
# http://www.halfcooked.com/mt/archives/000969.html
|
||||
self.connection = mysql.connect(
|
||||
hostname, username, password,
|
||||
database, cursorclass=cursors.DictCursor)
|
||||
|
||||
self.connection.autocommit(False) # for fast bulk inserts
|
||||
self.cursor = self.connection.cursor()
|
||||
|
||||
except mysql.Error, e:
|
||||
print "Connection error %d: %s" % (e.args[0], e.args[1])
|
||||
|
||||
def setup(self):
|
||||
try:
|
||||
# create fingerprints table
|
||||
self.cursor.execute("USE %s;" % self.database)
|
||||
self.cursor.execute(SQLDatabase.CREATE_FINGERPRINTS_TABLE)
|
||||
self.cursor.execute(SQLDatabase.CREATE_SONGS_TABLE)
|
||||
self.delete_unfingerprinted_songs()
|
||||
self.connection.commit()
|
||||
except mysql.Error, e:
|
||||
print "Connection error %d: %s" % (e.args[0], e.args[1])
|
||||
self.connection.rollback()
|
||||
|
||||
def empty(self):
|
||||
"""
|
||||
Drops all tables and re-adds them. Be carfeul with this!
|
||||
"""
|
||||
try:
|
||||
self.cursor.execute("USE %s;" % self.database)
|
||||
|
||||
# drop tables
|
||||
self.cursor.execute(SQLDatabase.DROP_FINGERPRINTS)
|
||||
self.cursor.execute(SQLDatabase.DROP_SONGS)
|
||||
|
||||
# recreate
|
||||
self.cursor.execute(SQLDatabase.CREATE_FINGERPRINTS_TABLE)
|
||||
self.cursor.execute(SQLDatabase.CREATE_SONGS_TABLE)
|
||||
self.connection.commit()
|
||||
|
||||
except mysql.Error, e:
|
||||
print "Error in empty(), %d: %s" % (e.args[0], e.args[1])
|
||||
self.connection.rollback()
|
||||
|
||||
def delete_orphans(self):
|
||||
try:
|
||||
self.cursor = self.connection.cursor()
|
||||
self.cursor.execute(SQLDatabase.DELETE_ORPHANS)
|
||||
self.connection.commit()
|
||||
except mysql.Error, e:
|
||||
print "Error in delete_orphans(), %d: %s" % (e.args[0], e.args[1])
|
||||
self.connection.rollback()
|
||||
|
||||
|
||||
def delete_unfingerprinted_songs(self):
|
||||
try:
|
||||
self.cursor = self.connection.cursor()
|
||||
self.cursor.execute(SQLDatabase.DELETE_UNFINGERPRINTED)
|
||||
self.connection.commit()
|
||||
except mysql.Error, e:
|
||||
print "Error in delete_unfingerprinted_songs(), %d: %s" % (e.args[0], e.args[1])
|
||||
self.connection.rollback()
|
||||
|
||||
def get_num_songs(self):
|
||||
"""
|
||||
Returns number of songs the database has fingerprinted.
|
||||
"""
|
||||
try:
|
||||
self.cursor = self.connection.cursor()
|
||||
self.cursor.execute(SQLDatabase.SELECT_UNIQUE_SONG_IDS)
|
||||
record = self.cursor.fetchone()
|
||||
return int(record['n'])
|
||||
except mysql.Error, e:
|
||||
print "Error in get_num_songs(), %d: %s" % (e.args[0], e.args[1])
|
||||
|
||||
def get_num_fingerprints(self):
|
||||
"""
|
||||
Returns number of fingerprints the database has fingerprinted.
|
||||
"""
|
||||
try:
|
||||
self.cursor = self.connection.cursor()
|
||||
self.cursor.execute(SQLDatabase.SELECT_NUM_FINGERPRINTS)
|
||||
record = self.cursor.fetchone()
|
||||
return int(record['n'])
|
||||
except mysql.Error, e:
|
||||
print "Error in get_num_songs(), %d: %s" % (e.args[0], e.args[1])
|
||||
|
||||
|
||||
def set_song_fingerprinted(self, song_id):
|
||||
"""
|
||||
Set the fingerprinted flag to TRUE (1) once a song has been completely
|
||||
fingerprinted in the database.
|
||||
"""
|
||||
try:
|
||||
self.cursor = self.connection.cursor()
|
||||
self.cursor.execute(SQLDatabase.UPDATE_SONG_FINGERPRINTED, song_id)
|
||||
self.connection.commit()
|
||||
except mysql.Error, e:
|
||||
print "Error in set_song_fingerprinted(), %d: %s" % (e.args[0], e.args[1])
|
||||
self.connection.rollback()
|
||||
|
||||
def get_songs(self):
|
||||
"""
|
||||
Return songs that have the fingerprinted flag set TRUE (1).
|
||||
"""
|
||||
try:
|
||||
self.cursor.execute(SQLDatabase.SELECT_SONGS)
|
||||
return self.cursor.fetchall()
|
||||
except mysql.Error, e:
|
||||
print "Error in get_songs(), %d: %s" % (e.args[0], e.args[1])
|
||||
return None
|
||||
|
||||
def get_song_by_id(self, sid):
|
||||
"""
|
||||
Returns song by its ID.
|
||||
"""
|
||||
try:
|
||||
self.cursor.execute(SQLDatabase.SELECT_SONG, (sid,))
|
||||
return self.cursor.fetchone()
|
||||
except mysql.Error, e:
|
||||
print "Error in get_songs(), %d: %s" % (e.args[0], e.args[1])
|
||||
return None
|
||||
|
||||
|
||||
def insert(self, key, value):
|
||||
"""
|
||||
Insert a (sha1, song_id, offset) row into database.
|
||||
|
||||
key is a sha1 hash, value = (song_id, offset)
|
||||
"""
|
||||
try:
|
||||
args = (key, value[0], value[1])
|
||||
self.cursor.execute(SQLDatabase.INSERT_FINGERPRINT, args)
|
||||
except mysql.Error, e:
|
||||
print "Error in insert(), %d: %s" % (e.args[0], e.args[1])
|
||||
self.connection.rollback()
|
||||
|
||||
def insert_song(self, songname):
|
||||
"""
|
||||
Inserts song in the database and returns the ID of the inserted record.
|
||||
"""
|
||||
try:
|
||||
self.cursor.execute(SQLDatabase.INSERT_SONG, (songname,))
|
||||
self.connection.commit()
|
||||
return int(self.cursor.lastrowid)
|
||||
except mysql.Error, e:
|
||||
print "Error in insert_song(), %d: %s" % (e.args[0], e.args[1])
|
||||
self.connection.rollback()
|
||||
return None
|
||||
|
||||
def query(self, key):
|
||||
"""
|
||||
Return all tuples associated with hash.
|
||||
|
||||
If hash is None, returns all entries in the
|
||||
database (be careful with that one!).
|
||||
"""
|
||||
# select all if no key
|
||||
if key is not None:
|
||||
sql = SQLDatabase.SELECT
|
||||
else:
|
||||
sql = SQLDatabase.SELECT_ALL
|
||||
|
||||
matches = []
|
||||
try:
|
||||
self.cursor.execute(sql, (key,))
|
||||
|
||||
# collect all matches
|
||||
records = self.cursor.fetchall()
|
||||
for record in records:
|
||||
matches.append((record[SQLDatabase.FIELD_SONG_ID], record[SQLDatabase.FIELD_OFFSET]))
|
||||
|
||||
except mysql.Error, e:
|
||||
print "Error in query(), %d: %s" % (e.args[0], e.args[1])
|
||||
|
||||
return matches
|
||||
|
||||
def get_iterable_kv_pairs(self):
|
||||
"""
|
||||
Returns all tuples in database.
|
||||
"""
|
||||
return self.query(None)
|
||||
|
||||
def insert_hashes(self, hashes):
|
||||
"""
|
||||
Insert series of hash => song_id, offset
|
||||
values into the database.
|
||||
"""
|
||||
for h in hashes:
|
||||
sha1, val = h
|
||||
self.insert(sha1, val)
|
||||
self.connection.commit()
|
||||
|
||||
def return_matches(self, hashes):
|
||||
"""
|
||||
Return the (song_id, offset_diff) tuples associated with
|
||||
a list of
|
||||
|
||||
sha1 => (None, sample_offset)
|
||||
|
||||
values.
|
||||
"""
|
||||
matches = []
|
||||
for h in hashes:
|
||||
sha1, val = h
|
||||
list_of_tups = self.query(sha1)
|
||||
if list_of_tups:
|
||||
for t in list_of_tups:
|
||||
# (song_id, db_offset, song_sampled_offset)
|
||||
matches.append((t[0], t[1] - val[1]))
|
||||
return matches
|
||||
224
dejavu/fingerprint.py
Normal file
224
dejavu/fingerprint.py
Normal file
|
|
@ -0,0 +1,224 @@
|
|||
import numpy as np
|
||||
import matplotlib.mlab as mlab
|
||||
import matplotlib.pyplot as plt
|
||||
import matplotlib.image as mpimg
|
||||
from scipy.io import wavfile
|
||||
from scipy.ndimage.filters import maximum_filter
|
||||
from scipy.ndimage.morphology import generate_binary_structure, iterate_structure, binary_erosion
|
||||
from dejavu.database import SQLDatabase
|
||||
import os
|
||||
import wave
|
||||
import sys
|
||||
import time
|
||||
import hashlib
|
||||
import pickle
|
||||
|
||||
class Fingerprinter():
|
||||
|
||||
IDX_FREQ_I = 0
|
||||
IDX_TIME_J = 1
|
||||
|
||||
DEFAULT_FS = 44100
|
||||
DEFAULT_WINDOW_SIZE = 4096
|
||||
DEFAULT_OVERLAP_RATIO = 0.5
|
||||
DEFAULT_FAN_VALUE = 15
|
||||
|
||||
DEFAULT_AMP_MIN = 10
|
||||
PEAK_NEIGHBORHOOD_SIZE = 20
|
||||
MIN_HASH_TIME_DELTA = 0
|
||||
|
||||
def __init__(self, config,
|
||||
Fs=DEFAULT_FS,
|
||||
wsize=DEFAULT_WINDOW_SIZE,
|
||||
wratio=DEFAULT_OVERLAP_RATIO,
|
||||
fan_value=DEFAULT_FAN_VALUE,
|
||||
amp_min=DEFAULT_AMP_MIN):
|
||||
|
||||
self.config = config
|
||||
database = SQLDatabase(
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_HOSTNAME),
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_USERNAME),
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_PASSWORD),
|
||||
self.config.get(SQLDatabase.CONNECTION, SQLDatabase.KEY_DATABASE))
|
||||
self.db = database
|
||||
|
||||
self.Fs = Fs
|
||||
self.dt = 1.0 / self.Fs
|
||||
self.window_size = wsize
|
||||
self.window_overlap_ratio = wratio
|
||||
self.fan_value = fan_value
|
||||
self.noverlap = int(self.window_size * self.window_overlap_ratio)
|
||||
self.amp_min = amp_min
|
||||
|
||||
def fingerprint(self, samples, path, sid, cid):
|
||||
"""Used for learning known songs"""
|
||||
hashes = self.process_channel(samples, song_id=sid)
|
||||
print "Generated %d hashes" % len(hashes)
|
||||
self.db.insert_hashes(hashes)
|
||||
|
||||
def match(self, samples):
|
||||
"""Used for matching unknown songs"""
|
||||
hashes = self.process_channel(samples)
|
||||
matches = self.db.return_matches(hashes)
|
||||
return matches
|
||||
|
||||
def process_channel(self, channel_samples, song_id=None):
|
||||
"""
|
||||
FFT the channel, log transform output, find local maxima, then return
|
||||
locally sensitive hashes.
|
||||
"""
|
||||
# FFT the signal and extract frequency components
|
||||
arr2D = mlab.specgram(
|
||||
channel_samples,
|
||||
NFFT=self.window_size,
|
||||
Fs=self.Fs,
|
||||
window=mlab.window_hanning,
|
||||
noverlap=self.noverlap)[0]
|
||||
|
||||
# apply log transform since specgram() returns linear array
|
||||
arr2D = 10 * np.log10(arr2D)
|
||||
arr2D[arr2D == -np.inf] = 0 # replace infs with zeros
|
||||
|
||||
# find local maxima
|
||||
local_maxima = self.get_2D_peaks(arr2D, plot=False)
|
||||
|
||||
# return hashes
|
||||
return self.generate_hashes(local_maxima, song_id=song_id)
|
||||
|
||||
def get_2D_peaks(self, arr2D, plot=False):
|
||||
|
||||
# http://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.morphology.iterate_structure.html#scipy.ndimage.morphology.iterate_structure
|
||||
struct = generate_binary_structure(2, 1)
|
||||
neighborhood = iterate_structure(struct, Fingerprinter.PEAK_NEIGHBORHOOD_SIZE)
|
||||
|
||||
# find local maxima using our fliter shape
|
||||
local_max = maximum_filter(arr2D, footprint=neighborhood) == arr2D
|
||||
background = (arr2D == 0)
|
||||
eroded_background = binary_erosion(background, structure=neighborhood, border_value=1)
|
||||
detected_peaks = local_max - eroded_background # this is a boolean mask of arr2D with True at peaks
|
||||
|
||||
# extract peaks
|
||||
amps = arr2D[detected_peaks]
|
||||
j, i = np.where(detected_peaks)
|
||||
|
||||
# filter peaks
|
||||
amps = amps.flatten()
|
||||
peaks = zip(i, j, amps)
|
||||
peaks_filtered = [x for x in peaks if x[2] > self.amp_min] # freq, time, amp
|
||||
|
||||
# get indices for frequency and time
|
||||
frequency_idx = [x[1] for x in peaks_filtered]
|
||||
time_idx = [x[0] for x in peaks_filtered]
|
||||
|
||||
if plot:
|
||||
# scatter of the peaks
|
||||
fig, ax = plt.subplots()
|
||||
ax.imshow(arr2D)
|
||||
ax.scatter(time_idx, frequency_idx)
|
||||
ax.set_xlabel('Time')
|
||||
ax.set_ylabel('Frequency')
|
||||
ax.set_title("Spectrogram of \"Blurred Lines\" by Robin Thicke");
|
||||
plt.gca().invert_yaxis()
|
||||
plt.show()
|
||||
|
||||
return zip(frequency_idx, time_idx)
|
||||
|
||||
def generate_hashes(self, peaks, song_id=None):
|
||||
"""
|
||||
Hash list structure:
|
||||
sha1-hash[0:20] song_id, time_offset
|
||||
[(e05b341a9b77a51fd26, (3, 32)), ... ]
|
||||
"""
|
||||
fingerprinted = set() # to avoid rehashing same pairs
|
||||
hashes = []
|
||||
|
||||
for i in range(len(peaks)):
|
||||
for j in range(self.fan_value):
|
||||
if i+j < len(peaks) and not (i, i+j) in fingerprinted:
|
||||
|
||||
freq1 = peaks[i][Fingerprinter.IDX_FREQ_I]
|
||||
freq2 = peaks[i+j][Fingerprinter.IDX_FREQ_I]
|
||||
t1 = peaks[i][Fingerprinter.IDX_TIME_J]
|
||||
t2 = peaks[i+j][Fingerprinter.IDX_TIME_J]
|
||||
t_delta = t2 - t1
|
||||
|
||||
if t_delta >= Fingerprinter.MIN_HASH_TIME_DELTA:
|
||||
h = hashlib.sha1("%s|%s|%s" % (str(freq1), str(freq2), str(t_delta)))
|
||||
hashes.append((h.hexdigest()[0:20], (song_id, t1)))
|
||||
|
||||
# ensure we don't repeat hashing
|
||||
fingerprinted.add((i, i+j))
|
||||
return hashes
|
||||
|
||||
def insert_into_db(self, key, value):
|
||||
self.db.insert(key, value)
|
||||
|
||||
def print_stats(self):
|
||||
|
||||
iterable = self.db.get_iterable_kv_pairs()
|
||||
|
||||
counter = {}
|
||||
for t in iterable:
|
||||
sid, toff = t
|
||||
if not sid in counter:
|
||||
counter[sid] = 1
|
||||
else:
|
||||
counter[sid] += 1
|
||||
|
||||
for song_id, count in counter.iteritems():
|
||||
song_name = self.song_names[song_id]
|
||||
print "%s has %d spectrogram peaks" % (song_name, count)
|
||||
|
||||
def set_song_names(self, wpaths):
|
||||
self.song_names = wpaths
|
||||
|
||||
def align_matches(self, matches, starttime, record_seconds=0, verbose=False):
|
||||
"""
|
||||
Finds hash matches that align in time with other matches and finds
|
||||
consensus about which hashes are "true" signal from the audio.
|
||||
|
||||
Returns a dictionary with match information.
|
||||
"""
|
||||
# align by diffs
|
||||
diff_counter = {}
|
||||
largest = 0
|
||||
largest_count = 0
|
||||
song_id = -1
|
||||
for tup in matches:
|
||||
sid, diff = tup
|
||||
if not diff in diff_counter:
|
||||
diff_counter[diff] = {}
|
||||
if not sid in diff_counter[diff]:
|
||||
diff_counter[diff][sid] = 0
|
||||
diff_counter[diff][sid] += 1
|
||||
|
||||
if diff_counter[diff][sid] > largest_count:
|
||||
largest = diff
|
||||
largest_count = diff_counter[diff][sid]
|
||||
song_id = sid
|
||||
|
||||
if verbose: print "Diff is %d with %d offset-aligned matches" % (largest, largest_count)
|
||||
|
||||
#from collections import OrderedDict
|
||||
#print OrderedDict(diff_counter)
|
||||
|
||||
# extract idenfication
|
||||
songname = self.db.get_song_by_id(song_id)[SQLDatabase.FIELD_SONGNAME]
|
||||
songname = songname.replace("_", " ")
|
||||
elapsed = time.time() - starttime
|
||||
|
||||
if verbose:
|
||||
print "Song is %s (song ID = %d) identification took %f seconds" % (songname, song_id, elapsed)
|
||||
|
||||
# return match info
|
||||
song = {
|
||||
"song_id" : song_id,
|
||||
"song_name" : songname,
|
||||
"match_time" : elapsed,
|
||||
"confidence" : largest_count
|
||||
}
|
||||
|
||||
if record_seconds:
|
||||
song['record_time'] = record_seconds
|
||||
|
||||
return song
|
||||
72
dejavu/recognize.py
Normal file
72
dejavu/recognize.py
Normal file
|
|
@ -0,0 +1,72 @@
|
|||
from multiprocessing import Queue, Process
|
||||
from dejavu.database import SQLDatabase
|
||||
from scipy.io import wavfile
|
||||
import wave
|
||||
import numpy as np
|
||||
import pyaudio
|
||||
import sys
|
||||
import time
|
||||
import array
|
||||
|
||||
class Recognizer(object):
|
||||
|
||||
CHUNK = 8192 # 44100 is a multiple of 1225
|
||||
FORMAT = pyaudio.paInt16
|
||||
CHANNELS = 2
|
||||
RATE = 44100
|
||||
|
||||
def __init__(self, fingerprinter, config):
|
||||
|
||||
self.fingerprinter = fingerprinter
|
||||
self.config = config
|
||||
self.audio = pyaudio.PyAudio()
|
||||
|
||||
def read(self, filename, verbose=False):
|
||||
|
||||
# read file into channels
|
||||
channels = []
|
||||
Fs, frames = wavfile.read(filename)
|
||||
wave_object = wave.open(filename)
|
||||
nchannels, sampwidth, framerate, num_frames, comptype, compname = wave_object.getparams()
|
||||
for channel in range(nchannels):
|
||||
channels.append(frames[:, channel])
|
||||
|
||||
# get matches
|
||||
starttime = time.time()
|
||||
matches = []
|
||||
for channel in channels:
|
||||
matches.extend(self.fingerprinter.match(channel))
|
||||
|
||||
return self.fingerprinter.align_matches(matches, starttime, verbose=verbose)
|
||||
|
||||
def listen(self, seconds=10, verbose=False):
|
||||
|
||||
# open stream
|
||||
stream = self.audio.open(format=Recognizer.FORMAT,
|
||||
channels=Recognizer.CHANNELS,
|
||||
rate=Recognizer.RATE,
|
||||
input=True,
|
||||
frames_per_buffer=Recognizer.CHUNK)
|
||||
|
||||
# record
|
||||
if verbose: print("* recording")
|
||||
left, right = [], []
|
||||
for i in range(0, int(Recognizer.RATE / Recognizer.CHUNK * seconds)):
|
||||
data = stream.read(Recognizer.CHUNK)
|
||||
nums = np.fromstring(data, np.int16)
|
||||
left.extend(nums[1::2])
|
||||
right.extend(nums[0::2])
|
||||
if verbose: print("* done recording")
|
||||
|
||||
# close and stop the stream
|
||||
stream.stop_stream()
|
||||
stream.close()
|
||||
|
||||
# match both channels
|
||||
starttime = time.time()
|
||||
matches = []
|
||||
matches.extend(self.fingerprinter.match(left))
|
||||
matches.extend(self.fingerprinter.match(right))
|
||||
|
||||
# align and return
|
||||
return self.fingerprinter.align_matches(matches, starttime, record_seconds=seconds, verbose=verbose)
|
||||
20
go.py
Normal file
20
go.py
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
from dejavu.control import Dejavu
|
||||
from ConfigParser import ConfigParser
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
|
||||
# load config
|
||||
config = ConfigParser()
|
||||
config.read("dejavu.cnf")
|
||||
|
||||
# create Dejavu object
|
||||
dejavu = Dejavu(config)
|
||||
dejavu.fingerprint("va_us_top_40/mp3", "va_us_top_40/wav", [".mp3"], 5)
|
||||
|
||||
# recognize microphone audio
|
||||
from dejavu.recognize import Recognizer
|
||||
recognizer = Recognizer(dejavu.fingerprinter, config)
|
||||
|
||||
# recognize song playing over microphone for 10 seconds
|
||||
song = recognizer.listen(seconds=1, verbose=True)
|
||||
print song
|
||||
159
performance.py
Normal file
159
performance.py
Normal file
|
|
@ -0,0 +1,159 @@
|
|||
from dejavu.control import Dejavu
|
||||
from dejavu.recognize import Recognizer
|
||||
from dejavu.convert import Converter
|
||||
from dejavu.database import SQLDatabase
|
||||
from ConfigParser import ConfigParser
|
||||
from scipy.io import wavfile
|
||||
import matplotlib.pyplot as plt
|
||||
import warnings
|
||||
import pyaudio
|
||||
import os, wave, sys
|
||||
import random
|
||||
import numpy as np
|
||||
warnings.filterwarnings("ignore")
|
||||
|
||||
config = ConfigParser()
|
||||
config.read("dejavu.cnf")
|
||||
dejavu = Dejavu(config)
|
||||
recognizer = Recognizer(dejavu.fingerprinter, config)
|
||||
|
||||
def test_recording_lengths(recognizer):
|
||||
|
||||
# settings for run
|
||||
RATE = 44100
|
||||
FORMAT = pyaudio.paInt16
|
||||
padding_seconds = 10
|
||||
SONG_PADDING = RATE * padding_seconds
|
||||
OUTPUT_FILE = "output.wav"
|
||||
p = pyaudio.PyAudio()
|
||||
c = Converter()
|
||||
files = c.find_files("va_us_top_40/wav/", [".wav"])[-25:]
|
||||
total = len(files)
|
||||
recording_lengths = [4]
|
||||
correct = 0
|
||||
count = 0
|
||||
score = {}
|
||||
|
||||
for r in recording_lengths:
|
||||
|
||||
RECORD_LENGTH = RATE * r
|
||||
|
||||
for tup in files:
|
||||
f, ext = tup
|
||||
|
||||
# read the file
|
||||
#print "reading: %s" % f
|
||||
Fs, frames = wavfile.read(f)
|
||||
wave_object = wave.open(f)
|
||||
nchannels, sampwidth, framerate, num_frames, comptype, compname = wave_object.getparams()
|
||||
|
||||
# chose at random a segment of audio to play
|
||||
possible_end = num_frames - SONG_PADDING - RECORD_LENGTH
|
||||
possible_start = SONG_PADDING
|
||||
if possible_end - possible_start < RECORD_LENGTH:
|
||||
print "ERROR! Song is too short to sample based on padding and recording seconds preferences."
|
||||
sys.exit()
|
||||
start = random.randint(possible_start, possible_end)
|
||||
end = start + RECORD_LENGTH + 1
|
||||
|
||||
# get that segment of samples
|
||||
channels = []
|
||||
frames = frames[start:end, :]
|
||||
wav_string = frames.tostring()
|
||||
|
||||
# write to disk
|
||||
wf = wave.open(OUTPUT_FILE, 'wb')
|
||||
wf.setnchannels(nchannels)
|
||||
wf.setsampwidth(p.get_sample_size(FORMAT))
|
||||
wf.setframerate(RATE)
|
||||
wf.writeframes(b''.join(wav_string))
|
||||
wf.close()
|
||||
|
||||
# play and test
|
||||
correctname = os.path.basename(f).replace(".wav", "").replace("_", " ")
|
||||
inp = raw_input("Click ENTER when playing %s ..." % OUTPUT_FILE)
|
||||
song = recognizer.listen(seconds=r+1, verbose=False)
|
||||
print "PREDICTED: %s" % song['song_name']
|
||||
print "ACTUAL: %s" % correctname
|
||||
if song['song_name'] == correctname:
|
||||
correct += 1
|
||||
count += 1
|
||||
|
||||
print "Currently %d correct out of %d in total of %d" % (correct, count, total)
|
||||
|
||||
score[r] = (correct, total)
|
||||
print "UPDATE AFTER %d TRIAL: %s" % (r, score)
|
||||
|
||||
return score
|
||||
|
||||
def plot_match_time_trials():
|
||||
|
||||
# I did this manually
|
||||
t = np.array([1, 2, 3, 4, 5, 6, 7, 8, 10, 15, 25, 30, 45, 60])
|
||||
m = np.array([.47, .79, 1.1, 1.5, 1.8, 2.18, 2.62, 2.8, 3.65, 5.29, 8.92, 10.63, 16.09, 22.29])
|
||||
mplust = t + m
|
||||
|
||||
# linear regression
|
||||
A = np.matrix([t, np.ones(len(t))])
|
||||
print A
|
||||
w = np.linalg.lstsq(A.T, mplust)[0]
|
||||
line = w[0] * t + w[1]
|
||||
print "Equation for line is %f * record_time + %f = time_to_match" % (w[0], w[1])
|
||||
|
||||
# and plot
|
||||
plt.title("Recording vs Matching time for \"Get Lucky\" by Daft Punk")
|
||||
plt.xlabel("Time recorded (s)")
|
||||
plt.ylabel("Time recorded + time to match (s)")
|
||||
#plt.scatter(t, mplust)
|
||||
plt.plot(t, line, 'r-', t, mplust, 'o')
|
||||
plt.show()
|
||||
|
||||
def plot_accuracy():
|
||||
# also did this manually
|
||||
secs = np.array([1, 2, 3, 4, 5, 6])
|
||||
correct = np.array([27.0, 43.0, 44.0, 44.0, 45.0, 45.0])
|
||||
total = 45.0
|
||||
correct = correct / total
|
||||
|
||||
plt.title("Dejavu Recognition Accuracy as a Function of Time")
|
||||
plt.xlabel("Time recorded (s)")
|
||||
plt.ylabel("Accuracy")
|
||||
plt.plot(secs, correct)
|
||||
plt.ylim([0.0, 1.05])
|
||||
plt.show()
|
||||
|
||||
def plot_hashes_per_song():
|
||||
squery = """select song_name, count(song_id) as num
|
||||
from fingerprints
|
||||
natural join songs
|
||||
group by song_name
|
||||
order by count(song_id) asc;"""
|
||||
sql = SQLDatabase(username="root", password="root", database="dejavu", hostname="localhost")
|
||||
cursor = sql.connection.cursor()
|
||||
cursor.execute(squery)
|
||||
counts = cursor.fetchall()
|
||||
|
||||
songs = []
|
||||
count = []
|
||||
for item in counts:
|
||||
songs.append(item['song_name'].replace("_", " ")[4:])
|
||||
count.append(item['num'])
|
||||
|
||||
pos = np.arange(len(songs)) + 0.5
|
||||
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.barh(pos, count, align='center')
|
||||
ax.set_yticks(pos, tuple(songs))
|
||||
|
||||
ax.axvline(0, color='k', lw=3)
|
||||
|
||||
ax.set_xlabel('Number of Fingerprints')
|
||||
ax.set_title('Number of Fingerprints by Song')
|
||||
ax.grid(True)
|
||||
plt.show()
|
||||
|
||||
#plot_accuracy()
|
||||
#score = test_recording_lengths(recognizer)
|
||||
#plot_match_time_trials()
|
||||
#plot_hashes_per_song()
|
||||
BIN
plots/accuracy.png
Normal file
BIN
plots/accuracy.png
Normal file
{kind=link}
Binary file not shown.
|
After 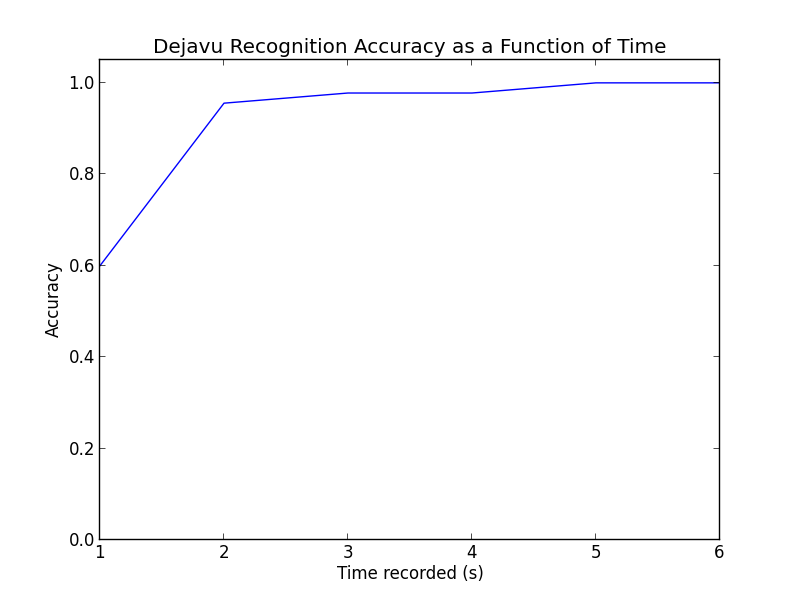
(image error) Size: 26 KiB |
BIN
plots/blurred_lines_spectrogram.png
Normal file
BIN
plots/blurred_lines_spectrogram.png
Normal file
{kind=link}
Binary file not shown.
|
After 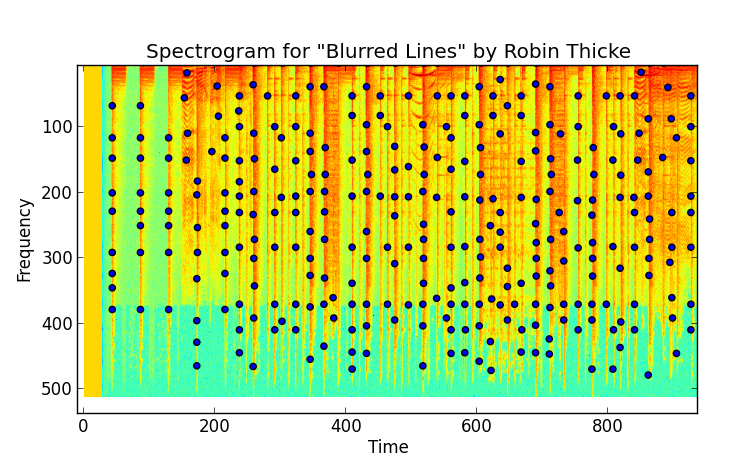
(image error) Size: 491 KiB |
BIN
plots/blurred_lines_vertical.png
Normal file
BIN
plots/blurred_lines_vertical.png
Normal file
{kind=link}
Binary file not shown.
|
After 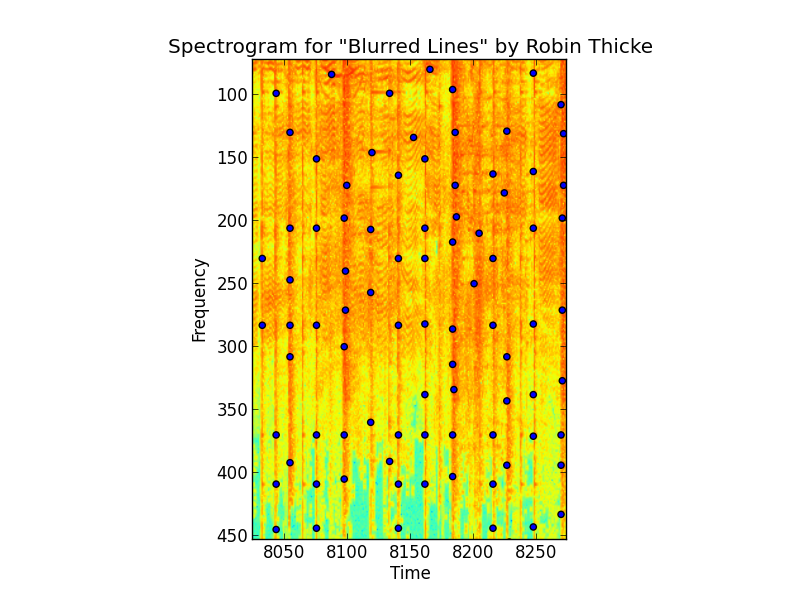
(image error) Size: 296 KiB |
BIN
plots/blurred_lines_zoomed.png
Normal file
BIN
plots/blurred_lines_zoomed.png
Normal file
{kind=link}
Binary file not shown.
|
After 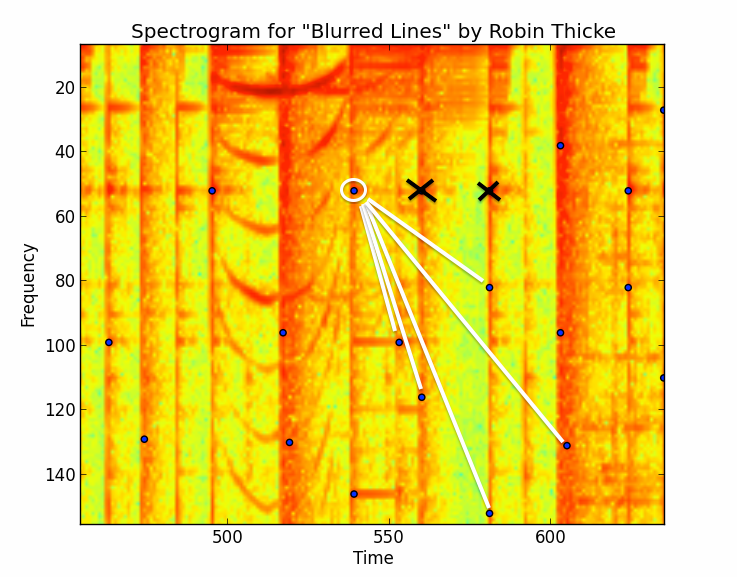
(image error) Size: 474 KiB |
BIN
plots/matching_time.png
Normal file
BIN
plots/matching_time.png
Normal file
{kind=link}
Binary file not shown.
|
After 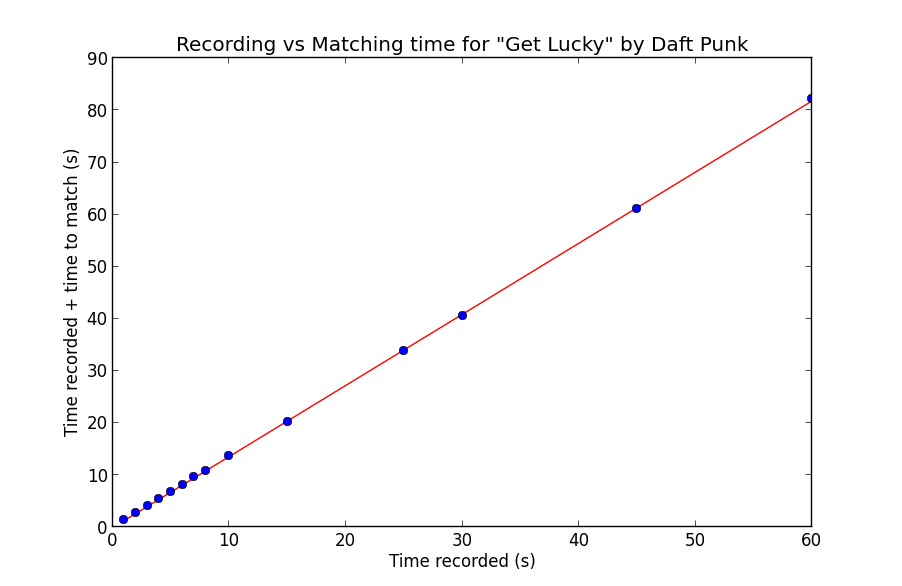
(image error) Size: 40 KiB |
Loading…
Add table
Reference in a new issue